Computing hardware is parallel. Everything from the Raspberry Pi to a supercomputer uses parallelism. The Chapel language and standard library make it easy to use that parallel hardware effectively.
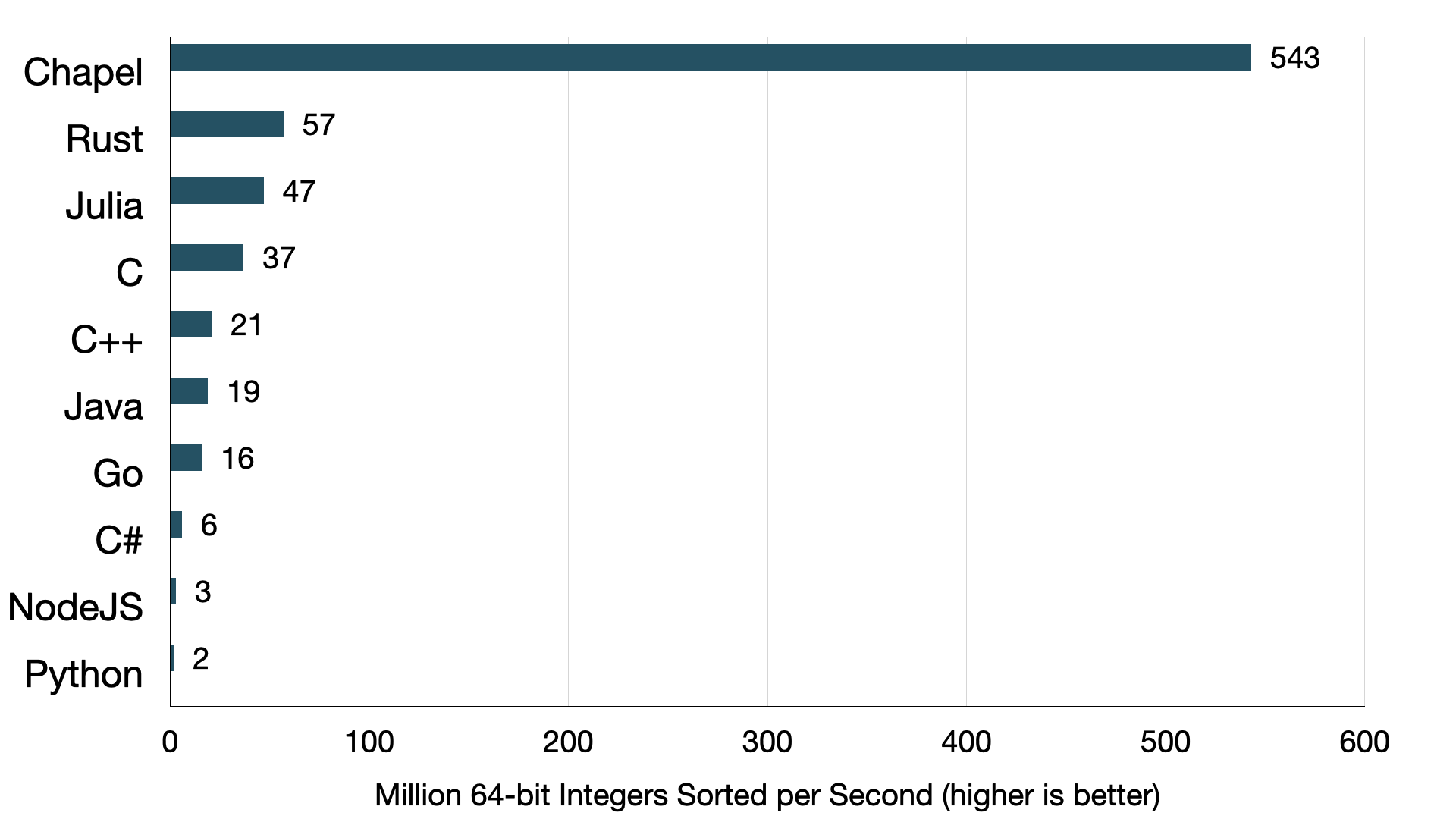
The Chapel standard library sort routine is at least 10 times
faster than any other standard library sort measured in this
benchmarking experiment. The reason: Chapel’s standard library sort
routine is parallel but the others are not. Chapel is designed for
parallel computing and its standard library is built to leverage that
parallelism.
Sorting 1 GiB of random 64-bit ints on a PC
Background
Sorting is an essential building block for many data processing tasks. It’s used to create the indexes that make searching fast, as well as in many other algorithms, such as finding repeated or unique items in a data set.
As a concrete example, sorting is fundamental to the data science workhorse GroupBy in the Pandas and Arkouda data analysis tools.
What is Arkouda?
For some applications, sorting can be the long pole in the tent, performance-wise. In fact, sorting is one of the first functions in Arkouda that needed a bit of optimization. After optimization, Arkouda’s custom sort routine has exceeded a rate of 1 GB/s per node on a large system with over 8000 nodes. Arkouda’s sort is focused on scaling well for really massive problem sizes. However, it has high constant overhead and is awkward to use when sorting variable-length data like strings.
This post is focused on the general-purpose sort implementations in
standard libraries for a variety of languages. Why focus on standard
library sort routines? For one thing, the standard library is more
likely to be used than other implementations. More importantly, we can
use the standard library sort to understand what a programming language
has to offer.
The Benchmark
This post compares sorting performance across a number of languages and
their standard libraries. The benchmark is simple: sort 1GiB of 64-bit
integers — that is, 128*1024*1024 integers.
Here are the details of the benchmark system, which is my PC:
- CPU: AMD Ryzen 9 7950X (4.5GHz, with 16 cores and 32 threads)
- Memory: 64 GiB of DDR5 memory (5200MT/s CL40)
- Motherboard: Gigabyte X670 Aorus Elite AX
- OS: Ubuntu 23.10

The Test Computer and Pawallel Computing Consultant
Even though this system is relatively inexpensive, parallelism matters for achieving performance on it.
For compilers and interpreters, I used the default versions available in
Ubuntu 23.10, except for the version of Chapel. I used a pre-release
version of the March 2024 release of Chapel because I recently improved
its sort implementation to be more parallel.
software versions
- C and C++:
gccandg++13.2.0 - C#:
mcsandmono6.8.0.105 - Chapel: 1.34, pre-release
- Go:
go1.21.1 - Java:
javacandjava17.0.9 - Julia:
julia1.10.0 - NodeJS:
node18.13.0 - Python:
python33.11.6 - Python NumPy: 1.24.2
- Rust:
cargoandrustcversion 1.71.1
Measuring Chapel’s Sort Performance
Here is the program I’m using to measure Chapel’s sort performance on this system:
|
|
To run this Chapel program, we need to compile it first. Since we’re
interested in benchmarking performance, we need to make sure to throw
--fast to enable more optimization and turn off execution-time safety
checks:
$ chpl sort-random.chpl --fast
Now we can run it:
$ ./sort-random
Sorted 134217728 elements in 0.246093 seconds
545.394 million elements sorted per second
This is a pretty straightforward program. Probably the most complicated
thing about it is timing and printing the performance! But, because Chapel
is designed for parallelism, it’s quite parallel. The fillRandom(A) call
generates random values in parallel and stores them into the array A.
And the sort(A) call runs a parallel sort. It’s important to note that
you don’t have to know anything at all about parallel computing in order
to make use of these parallel routines.
Python’s Sort Performance
Let’s look at a Python version of our sort benchmark:
import random
import time
n = 128*1024*1024
array = [random.randint(0, 0xffffffffffffffff) for _ in range(n)]
start = time.time()
array.sort()
stop = time.time()
elapsed = stop-start
print ("Sorted", n, "elements in", elapsed, "seconds")
print (n/elapsed/1_000_000, "million elements sorted per second")
$ python3 python-sort-random.py
Sorted 134217728 elements in 56.063706398010254 seconds
2.394021669690456 million elements sorted per second
That’s quite a bit slower. The Chapel code is about 200x faster while being similarly easy to write or read. Often, optimizing a program makes it more complex and harder to maintain, but that’s not the case here. The performance of the Chapel version comes for free.
You might be curious about a version using NumPy. Since NumPy isn’t in the Python standard library, the main graph of this post doesn’t include it. But, it is common enough readers are likely to be curious about it. A NumPy version improves upon the performance of the Python version, but the Chapel benchmark still sorts about 25x faster.
(click to see the NumPy version)
import numpy
import random
import time
n = 128*1024*1024
array = numpy.random.randint(0, 0xffffffffffffffff, size=n, dtype=numpy.uint64)
start = time.time()
array.sort()
stop = time.time()
elapsed = stop-start
print ("Sorted", n, "elements in", elapsed, "seconds")
print (n/elapsed/1_000_000, "million elements sorted per second")
$ python3 numpy-sort-random.py
Sorted 134217728 elements in 6.323578834533691 seconds
21.22496319125867 million elements sorted per second
Results
This chart shows the complete results:
Sorting 1GiB of random 64-bit ints on a PC
In making this chart, I made 5 measurements for each language. The chart shows the average of these.
Note that NodeJS crashed with an out-of-memory-error for this problem size, so I halved the problem size for the NodeJS measurement here.
The fastest alternative to Chapel here is Rust. But, the Chapel sort is still quite a bit faster — about 10x faster.
The code and commands I used to benchmark each of these are available in the Chapel test directory.
Parallel Sorting
Most of the performance gain from the Chapel sort comes from it being
parallel. None of the benchmarks in other languages made use of the 16
cores of my system. According to the top command, they were all running
in 1 thread.
Many of these languages support some form of parallelism. So, why don’t
they have a parallel sort? In some cases, making the sort parallel by
default might cause problems for existing applications by creating
unwanted threads (C, C++, Rust). In other cases, the sort probably
could be parallel but currently isn’t (Julia, Python). If you’re reading
this and have more insight into the situation with a particular language,
please let me know.
Chapel’s sort implementation enables the use of common parallel
hardware — including laptops, workstations, and of course clusters and
supercomputers. The sort implementation uses multi-core CPUs today but
we expect to extend it to support distributed memory and GPUs.
an aside about hardware threads
If you are curious about hardware parallelism, note that we can actually get slightly more performance for the Chapel benchmark by using more of the parallelism available in the hardware. The CPU on my system has 16 cores and 32 hardware threads. These additional threads can sometimes help with memory-bound applications (like sorting). However, by default, Chapel will only use 1 thread per core because that configuration has shown to provide better performance for most applications. We can request 1 Chapel thread per hardware thread like this:
$ CHPL_RT_NUM_THREADS_PER_LOCALE=MAX_LOGICAL ./chapel-sort-random
Sorted 134217728 elements in 0.238736 seconds
562.201 million elements sorted per second
See also Chapel’s documentation about controlling the number of threads.
By the way, the Chapel implementation also supports generating the random array values in parallel. That allows the array-generation step to be about 900x faster than Python. But, Chapel’s random number generator is a subject for another post.
Why can the Chapel standard library include parallel routines to sort
or generate random numbers? A key factor here is that Chapel supports
composable parallelism. Library functions can create new tasks, where the
number of tasks is only limited by memory. In contrast, for many programming
systems, threads are heavy-weight objects and subject to an operating
system limit. Since Chapel is designed to support nested parallelism,
you can even call the parallel sort from within a parallel loop.
In such a nested parallelism scenario, the Chapel library can limit parallelism when the cores are already busy. If we are curious about the performance of this benchmark on just 1 core, we can use a command-line flag to request that Chapel use one core for data-parallel operations:
$ ./sort-random --dataParTasksPerLocale=1
Sorted 134217728 elements in 2.10068 seconds
63.8924 million elements sorted per second
Even without parallelism, the Chapel sort is faster than the other
languages measured in this post. One reason is that it uses a radix sort,
which is rare for a standard library. Chapel’s great support for generic
programming makes using a radix sort convenient. That’s the subject for
the next post in this series.
In Conclusion
We need a parallel language because the world of computing hardware is parallel. Anything less leaves a lot of performance on the floor, whether in the server room or your home study. Chapel is a parallel language that is ready to help you solve problems where performance is critical. As the example in this post showed, you can even benefit from this parallel language if you are new to parallel computing.
Give Chapel a try and let us know what you think!
(If you have any comments, questions, or observations about this post, please direct them to this Discourse thread).